* indicates equal contribution.
A proof-of-concept study of direct magnetic resonance imaging-based proton dose calculation for brain tumors via neural networks with Monte Carlo-comparable accuracy
Physics and Imaging in Radiation Oncology (phiRO), 2025
Presents the MIND neural dose engine that predicts individual proton pencil beam dose distributions directly from MR images,
achieving a median 99.8% gamma pass rate at 1 mm/1% while reducing computation to about 3 ms per beam.
Neural network-driven direct CBCT-based dose calculation for head-and-neck proton treatment planning
Physics in Medicine & Biology (PMB), 2025
Develops an xLSTM-based CBCT neural dose engine (CBCT-NN) that predicts proton dose directly on CBCT images,
achieving 95.1 ± 2.7% gamma pass rates at 2 mm/2% and under-3-minute computation for complete head-and-neck plans,
enabling adaptive workflows without synthetic CT or complex correction pipelines.
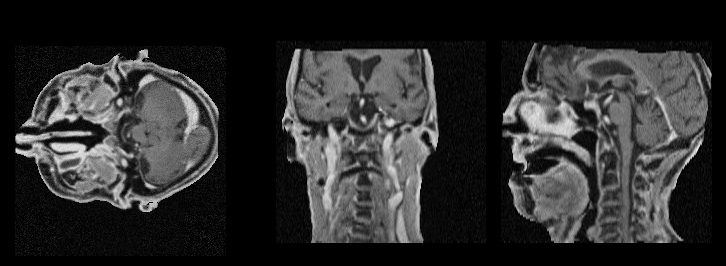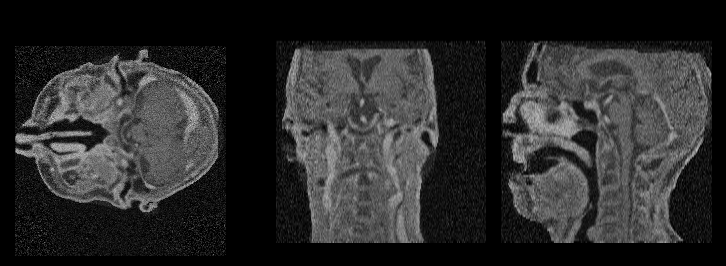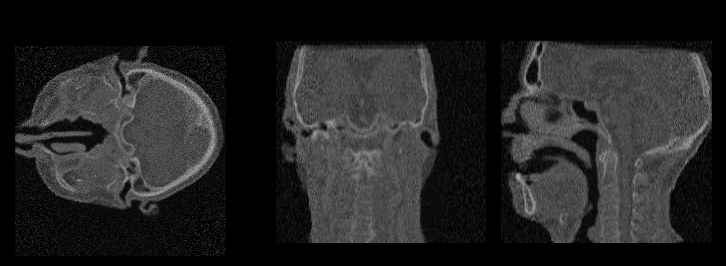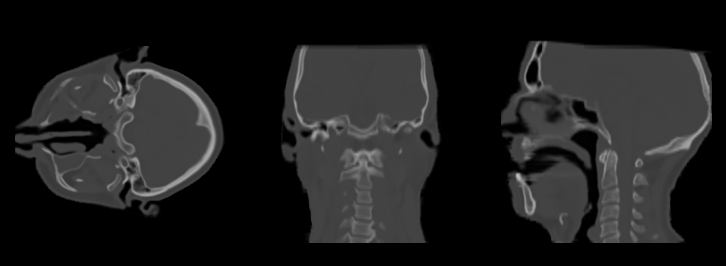
Diffusion Schrödinger bridge models for high-quality MR-to-CT synthesis for proton treatment planning
Medical Physics, 2025
Introduces DSBM, modeling an entropic optimal transport (Schrödinger bridge) between MR and CT distributions
to achieve superior geometric fidelity and dosimetric accuracy in MR-only proton therapy.
Neural graphics primitives-based deformable image registration for on-the-fly motion extraction
International Conference on the Use of Computers in Radiation Therapy (ICCR), 2024
Adapts Instant Neural Graphics Primitives and multi-resolution hash encoding to enable on-the-fly motion extraction
with sub-second inference for accurate 4D dose accumulation.
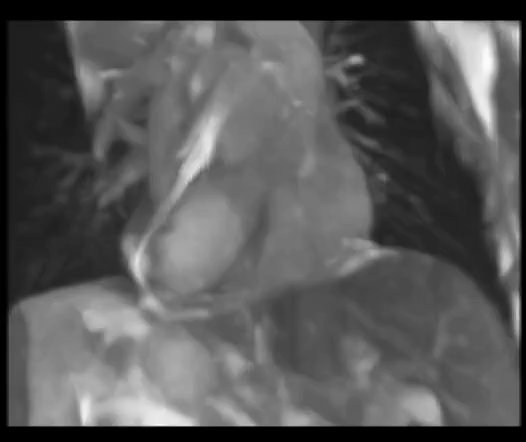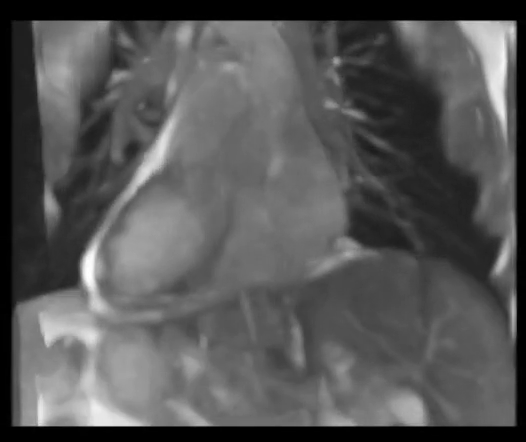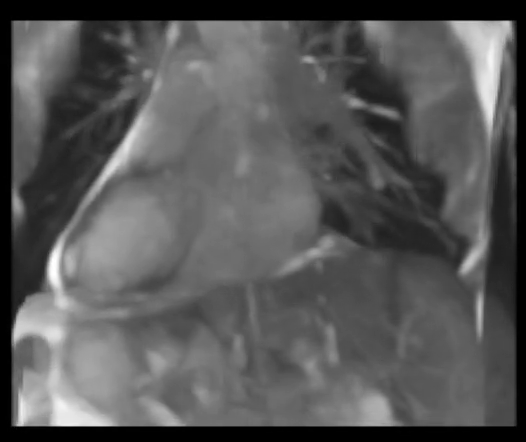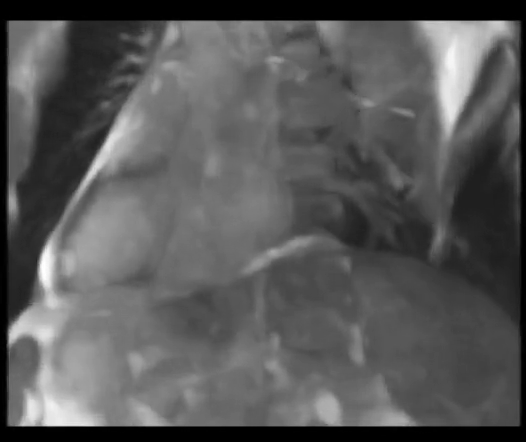
CPT-4DMR: Continuous sPatial-Temporal representation for 4D-MRI reconstruction
Xinyang Wu*,
Muheng Li*, Xia Li*, Orso Pusterla, Sairos Safai, Philippe C. Cattin,
Antony Lomax,
Ye Zhang
Preprint, 2025
Proposes a continuous spatio-temporal representation f(x, y, z, t) for 4D-MRI, enabling reconstruction
at arbitrary respiratory phases and reducing binning artifacts.
Diffusion-SDF: Text-to-shape via voxelized diffusion
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Proposes Diffusion-SDF, combining an SDF autoencoder with voxelized diffusion for text-to-shape synthesis,
and extends it to text-conditioned shape completion and manipulation.
Bridge-Prompt: Towards ordinal action understanding in instructional videos
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Introduces Bridge-Prompt, a prompt-based framework for ordinal action understanding that models
semantics across multiple adjacent correlated actions in instructional videos.
Uncertainty-aware representation learning for action segmentation
International Joint Conference on Artificial Intelligence (IJCAI), 2022
Proposes an uncertainty-aware representation learning framework to capture transitional expressions
between action periods, improving robustness in action segmentation.
Order-constrained representation learning for instructional video prediction
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2022
Presents an Order-Constrained Representation Learning (OCRL) approach with a StepNCE contrastive loss
to predict future actions from partially observed instructional videos in a weakly-supervised manner.